Table of Contents
常见的需求是前端解析 epub(使用 epub.js),所以找导出 epub 的库就没那么容易了。比如 js-epub-maker,可以用,但好几年不维护了。
引入无效
根据文档,npm 安装:
npm install epub-maker --save
但不管是使用 require 还是 import,引入都无效。并且就算引入了,还是要在 index.html 里用标签的形式引入一堆依赖文件。没办法,我只能把文件都从包里拷贝出来,放到 public 目录下,通过 script 引入。
汉字名称无效
根据文档介绍,可以通过 new EpubMaker().withTitle(‘title’) 设置书名。但是,很多字符会被过滤掉,比如中文。因为库用了一个正则过滤掉了可能导致文件名错误的字符:
function simpleSlugify(str) {
return str.toLowerCase().replace(/\s\W/g, '-');
}
于是,空格和不属于 A-Za-z0-9_ 的字符都过滤掉了。
添加文件
epub 里不会只有文字,很多时候还需要添加图片、css 文件等。对于这些文件,库是用 ajax 获取的。问题来了,我的文件都已经是 base64 字符串了,已经不需要远程获取了,这该怎么办呢?
这时,我想到了 blob。我可以将 base64 封装成文件,然后转成 url。
let blob = dataURItoBlob(item.data) epub.withAdditionalFile(URL.createObjectURL(blob), 'images', item.name)
/**
* base64 to blob二进制
*/
export function dataURItoBlob(dataURI) {
var mimeString = dataURI.split(',')[0].split(':')[1].split(';')[0]; // mime类型
var byteString = atob(dataURI.split(',')[1]); //base64 解码
var arrayBuffer = new ArrayBuffer(byteString.length); //创建缓冲数组
var intArray = new Uint8Array(arrayBuffer); //创建视图
for (var i = 0; i < byteString.length; i++) {
intArray[i] = byteString.charCodeAt(i);
}
return new Blob([intArray], { type: mimeString });
}
/**
*
* blob二进制 to base64
**/
export function blobToDataURI(blob, callback) {
var reader = new FileReader();
reader.onload = function (e) {
callback(e.target.result);
}
reader.readAsDataURL(blob);
}
上面是图片,css 也是差不多的:
let blob = dataURItoBlob(stylesheet.data) epub.withStylesheetUrl(URL.createObjectURL(blob))
就这样,添加文件的问题解决了。
xml 解析报错
这个库提供了两个 epub 模板。idpf-wasteland 和 lightnovel。前者是 xml,后者是 html。一开始我用的 xml 格式的。导出后阅读器打不开。用 Sigil 看了下,每个页面都报错。比如:
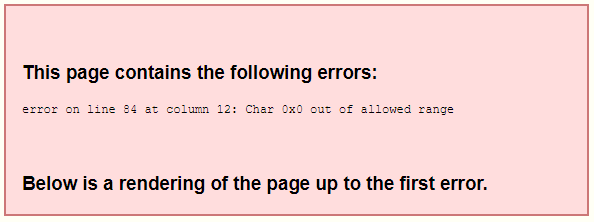

0x0 在 xml 里是非法字符(0x00-0x20 都是非法字符)。于是只能先用正则对内容过滤,然后再导出。可是右碰到了下面的报错:

  这种以 & 开头,; 结尾的是字符实体,常用来表达 xml 和 html 里会引起解析错误的字符。上面的报错表示,xml 遇到了 &,以为是字符实体的表示,但后面没有正确表示字符实体,然后就报错了。没办法,接着正则过滤:
// 非字符实体开头的 & 转为字符实体,否则 '& ' 这种也会导致 xml 解析报错 item.definition = item.definition.replace(/&(?!#?[a-z0-9]+;)/g, '&')
解决了字符实体,可还是没能成功导出。因为 xml 对语法比较严格,而我的内容不规范,标签不闭合、属性大写、属性值没有引号。但这个内容来自于 mdx 文件。
鉴于解决难度较大,所以我就考虑切换到 html 模板。
html 模板不存在
上面说过,库提供了两个模板。但当我使用 html 模板的时候,发现模板不存在。因为有两个模板的代码还没有发布到 npm 上。没办法,只能将 github 上的代码下载下来,然后扔到 public 里通过 script 引入。
本因为会顺利一些,但没想到,添加图片报错了,直接无法导出。
重构库
我看了下库的源码。代码并不多,我完全可以在我的项目里重写一遍。以此解决碰到的问题——中文被过滤掉、图片引入报错等。
因为 xml 太不友好,所以我只保留了 html 模板——lightnovel。代码用 es6 语法重构。
因为 webpack 会对 html、css 文件进行处理,而我希望 webpack 只将 lightnovel 的文件作为纯文本引入。所以需要修改 webpack 配置。
module.exports = {
chainWebpack: config => {
config.module
.rule('css')
.exclude
.add(/epub_templates/)
config.module
.rule('epub_dir')
.test(/epub_templates/)
.use()
.loader('raw-loader')
.end()
},
}
在重构 epub-maker 之后,我发觉图片引入报错是因为我参数写错了,原来的库添加图片没有问题。不过无所谓,即使因为中文命名的问题也是要重构的。
在经过这一些列操作后,我终于导出了可以阅读的 epub。(ps:因为源内容的不规范,部分 epub 阅读器还是无法打开。)