https://segmentfault.com/a/1190000011425787
https://kod.dowhat.top/data/User/admin/home/docs/documents/lzw.htm
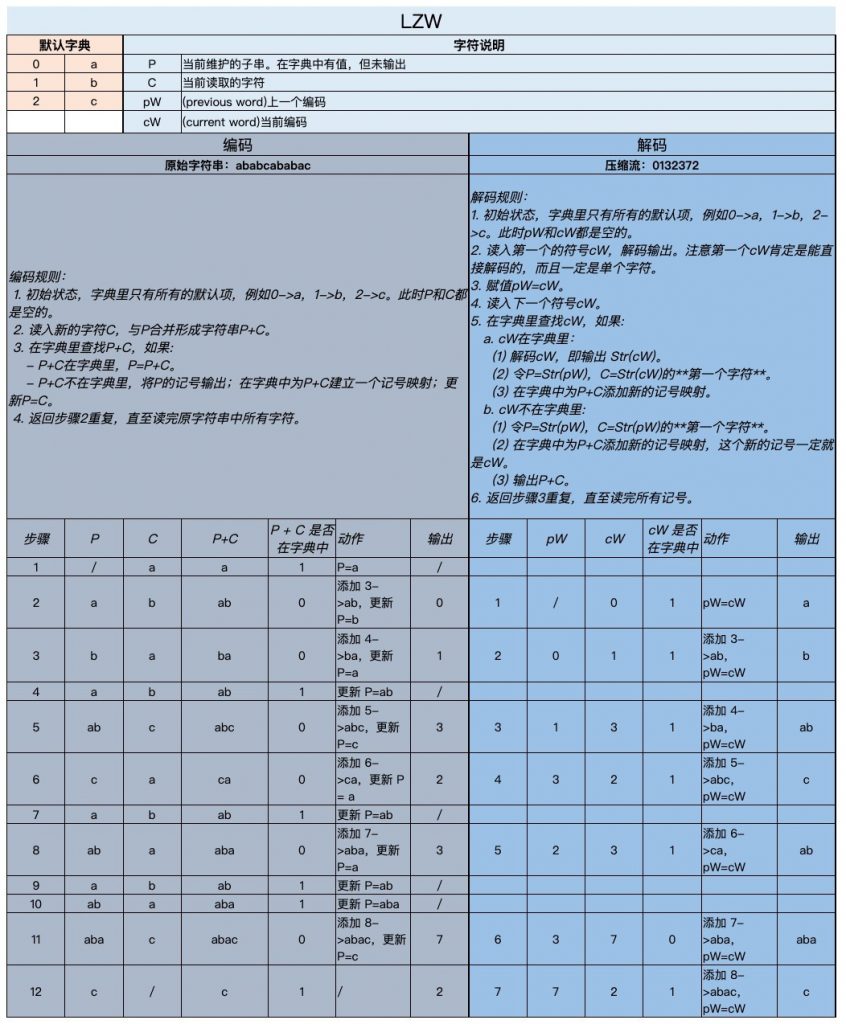
- 编码时的 P 到底是什么?
这个 P 代表了待编码字符串中从头开始与字典中字符串匹配的最长子串。当遇到 P+C 不在字典中的时候,说明 P 已经最长,需要输出。然后,给 P+C 添加一个记录。下一步,从 C 开始匹配。 - 字典增加和压缩流有什么关系?
从编码规则可知,只有当字典中不存在 P+C 的时候,才会输出一个压缩后的编码(P),同时添加一条新的记录(P+C)。所以这两者是同步增长的。编码流里的编码也都是在当前字典中存在的。 - 解码时遇到的编码在不在字典中都需要添加记录是为什么?
因为编码的时候,只有遇到新记录的时候才会输出压缩码。即,解码的时候每读一个压缩码都意味着在编码的时候添加了一条记录,所以解码也需要添加记录,更新字典。 - 为什么解码时的第一个压缩码一定是默认字典里有的?
编码的时候只有遇到不存在的记录才会输出。比如,ab 不存在,输出 a。即,xxxy 不存在时,xxx 是已知的。不存在 xxxy 和 xxxyy 都不存在时遇到 xxxyy 的情况。因为 xxxyy 之前一定会遇到 xxxy,而这时会添加 xxxy 这条记录。 - 为什么解码的时候添加记录会慢一步?
因为在第一步时候还不知道要添加哪条记录,当读到第二个压缩码的时候,才知道编码时的第一个添加了哪个记录。
比如,解码第一步遇到 a。这个 a 在编码肯定是因为 ax 不在字典中才输出的。但 x 是多少这时还不知道。解码第二步遇到 b。这个 b 在编码时肯定是因为 by 不在字典中才输出的。而根据编码规则可以知道,a 输出后就以 x 开头了。即 by = xy。则 x 为 b。所以在解码第二步添加了 ab 记录——这个 b 就是压缩码 cW 对应字符串的第一位。即,设 abc 为已知,xy 为未知,解码时读到 abc,得知编码时产生了一条 abcx 的记录,并以 x 开头继续匹配,直到 xabcy 不存在,输出 xabc。下一步读到 eabc,则 x 为 e,需要添加的记录是 abce。
上面是 cW 在字典中的情况。cW 不在字典中又是怎么回事呢?回到编码过程。编码时,abcx 不在,添加这条记录,输出 abc。解码时,abcx 的记录要慢一步。应该在读取下一个压缩码的时候记录 abcx。但这时遇到了 Str(cW) 不存在的情况。说明编码阶段,输出 abc 之后的下一个输出就是 abcx——刚记录就用上了。而我们知道,编码阶段输出 abc 之后就以 x 开始匹配了,所以,x = a,解码阶段遇到不存在的就用 Str(pW)+Str(cW)[0] 记录并输出。